スタッフブログ
おはようございます。
システムエンジニアの鈴木です。
どんよりとした朝になりました。皆さんはいかがお過ごしでしょうか?
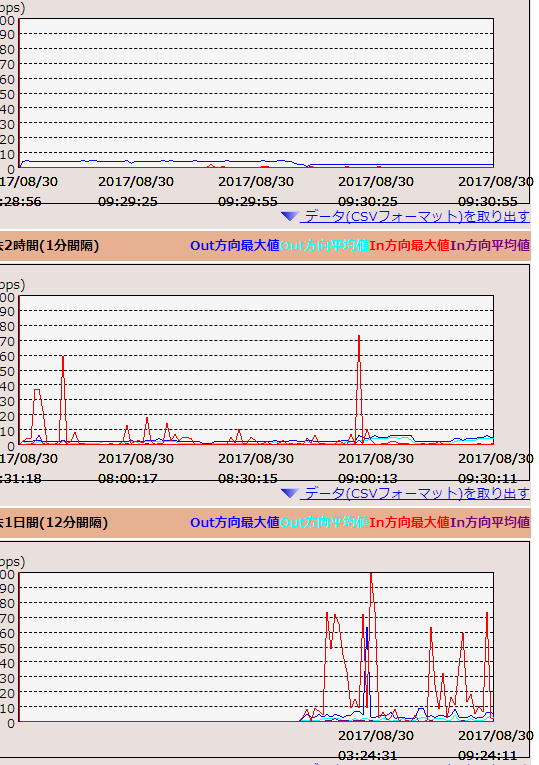
さてさて、先日日曜日ぐらいからお騒がせしている不正アクセスによるサーバー障害についてですが、昨日も午後9時すぎに5分程度発生いたしました。
緊急に状況を確認し、ログの解析などから、サーバーネットワークを司る装置(ルーター)が不正アクセスの処理に追いつかず、CPUが100%の状態になり、自動復旧のために機器が再起動を繰り返す事で、通信障害が発生している事を突き止めました。
ネットワークのトラフィックをログから参照すると、回線上十分な容量を確保できていましたので、集中してアクセスする事でパンクしたものではない事がわかります。
ではなぜCPUが暴走する原因になったのでしょうか?
不正アクセスの数は回線容量よりも少ないアタックではありましたが、ほぼ同時に多数の地域から集中的にアクセスされ、装置が不正アクセスと判断すると、ブロック及び管理者に通知する処理を自動で行います。この処理が同時に起こり、装置がフリーズ状態になる事で再起動がかかってしまうというものが原因のようでした。
このことから、この装置の挙動を変更してCPUに負担をかけない仕様に変更したところ、同様のネットワークトラフィックがかかってもフリーズしない事がわかりました。
この装置は、弊社OEMで提供しているシステムのサーバー5台、一部のサーバー監視、VTOS,VTSVサービス、SSLサービス、クラウドファイルサービスに直結しているため、これらのサービスで障害が発生していた事も判明いたしました。
装置の挙動変更後の本日、午前0時~午前9時の間のログでは、今のところ異常はみられない事が確認できました。
今後、同様の負荷がかかるか継続的な監視を強化し、慢性的になるようであれば、装置の強化を検討しなければならないようです。
皆様には大変ご不便をおかけいたしました事お詫び申し上げます。